It is hardly news that we live in an era when readily accessible AIs are catalysing a period of economic disruption. When used thoughtfully, Large Language Models allow for dramatic streamlining of production pipelines, reducing the cost of drafting, coding, summarising, analysing and automating routine knowledge work.
Yet most discussion still centres on frontier cloud models: ChatGPT, Claude, Gemini and their peers. These systems are powerful, polished and increasingly embedded into professional workflows. However, dependence on external APIs comes with external drawbacks – although proprietary closed-weight models often come with a high quality ecosystem of readily callable tools and capabilities, not to mention models that run into the hundreds of billions of parameters, there are drawbacks. Users may experience degraded performance, and costs may balloon at a moments’ notice. The alternative? Local LLMs.
By local LLMs, I mean models that run directly on your own machine rather than through a cloud API. Instead of sending prompts to an external server, the model runs on your laptop, desktop or private server. This changes the economics and privacy assumptions of AI use. It also shifts more responsibility onto the user, because local models vary significantly in speed, reliability and instruction-following ability.
For this article, I tested a set of local models on a MacBook Pro with an M4 Pro chip and 48 GB of unified memory, using Ollama and LM Studio. The models were:
| Model | Size | USP |
|---|---|---|
| Qwen 3.6 35B | 35B – A3B | Largest general-purpose model tested |
| Gemma 4 31B | 31B | Large dense general assistant model |
| Gemma 4 26B | 26B – A4B | Gemma 4 tested with Model of Experts architecture |
| Qwen 3.5 4B | 9B | Small Qwen speed baseline |
| Gemma 4 4B | 4B | Lightweight model baseline |
I’m not trying to create a definitive academic benchmark – more than enough of those are already out there. Instead, I’m trying to answer a practical question – which models provide the most real-world utility, where do they start to break, and what practical differences can we notice between small 4 Billion parameter models designed to run on consumer-end hardware and larger 20 to 30 billion parameter models that stretch the limits?
Why this model set is interesting
This group of models creates a useful contrast.
At one end are Qwen 3.6 35B, Gemma 4 31B and Gemma 4 26B. These are the latest and ‘highest scoring’ open weight LLMs on many benchmarks as of April 2026. They’re large enough to be genuinely interesting as local alternatives to cloud models, but also large enough to test the limits of laptop-based inference. They should, in theory, be better at reasoning, instruction-following and complex writing than smaller models. But that extra capability comes at a cost: more memory pressure, slower generation, longer load times and a greater chance that the model feels heavy in ordinary use. It’s also worth noting the presence of Gemma 4 31B – a ‘dense’ LLM. Some models use a ‘model of experts approach – they select a small subset of their parameters to conduct inference on a query depending on what the model deduces the nature of the query is. In contrast, Gemma 4 31B utilises all of its’ parameters to respond to a query, which may result in a greater ‘depth’, albeit at a significantly slower inference rate.
At the other end are Qwen 3.5 9B and Gemma 4 4B. These are not expected to beat the larger models on raw intelligence. Their purpose is different. They test whether a small local model can be fast enough, responsive enough and sufficiently competent for lightweight tasks such as summarisation, drafting, simple classification or coding assistance – determining whether the average consumer can derive any real benefit from current locally hosted open weight LLMs.
This is the central trade-off in local AI. The best model is not necessarily the largest. A model that is theoretically stronger but slow enough to interrupt workflow may be less useful than a smaller model that gives acceptable answers instantly.
The testing setup
The tests were run on:
GPU: Apple M4 Pro (20 core)Memory: 48 GB unified memoryHarness: LM Studio
I chose to use LM Studio as the harness through which I ran these LLMs rather than other tools such as Ollama owing to their superior machine protection safeguards and their GUI with built-in tokens-per-second tracking and temperature adjustment capabilities. You can try it yourself here
Important note – I chose to download and utilise all models at a ‘4 bit’ quantisation level. What this means is that the ‘weights’ stored in vector form that make up the structure of LLMs have been stored as 4 bit numbers, truncating their original 32 bit format. This has cut the ‘accuracy’ of these models by between 2 and 5%, however, it leads to massive memory savings. This makes it possible to run the entire suite of publicly available Gemma 4 and Qwen 3.6 LLMs on my machine.
The comparison focused on practical use rather than abstract benchmark scores. I looked at:
| Category | What I was judging |
|---|---|
| Response Format (20%) | Whether its’ response is in a valid .JSON format |
| Adherence to Schema (20%) | Whether it obeyed detailed constraints |
| Factual Correctness (40% weighting) | Whether the substance of the response is in accordance with reality |
| Compliance with Constraints (20% weighting) | Adherence to safety layer, resistance to attempted prompt injections, following of specified instructions in response. |
I asked each model to execute the same 10 tasks, weighting each task equally. The tasks range from simple key term extraction from JSON files to prompt injection resistance testing and reasoning/justification stress testing. The full list of prompts is available here. All models are being run in ‘reasoning’ mode, leading to greater accuracy at the expense of longer periods of inference.
Model 1: Gemma 4 E4B

The Gemma 4 4B model is Google’s smallest latest-generation open weight model. On paper, we’d be expecting it to struggle with more complex tasks, breaking down slightly as the prompts become more complex.
| Detail | Result |
|---|---|
| Model | Gemma 4 E4B |
| Context length | 128,000 tokens |
| Temperature | 0 |
| Speed | ~52 tokens/second |
| Memory pressure | 12.69 GB with full context window (5.89 GB minimum) |
| Scorecard | Score |
|---|---|
| Question 1 | 10 |
| Question 2 | 9.5 |
| Question 3 | 7 |
| Question 4 | 9 |
| Question 5 | 6 |
| Question 6 | 9 |
| Question 7 | 6 |
| Question 8 | 8.75 |
| Question 9 | 9 |
| Question 10 | 7 |
| Total: | 81.25/100 |
General impression
What a model! On paper, at 4 billion parameters this ought to be the least capable of the models we’re testing today. However, it achieved a respectable score of 81.25 out of 100. Whilst it did struggle in some areas, notably in debugging a test python program – with it being unable to identify the locations and nature of some bugs in question 5, and in Question 7 it incorrectly described itself as being capable of answering a question on ambiguous gender pronouns despite going on the clearly state the reasons it was unable to do so. Nevertheless, at a size that fits onto many consumer-range laptops, operating at speeds of over 50 tokens per second on my machine, the model provided a solid baseline. It’s also noteworthy how well the model was able to utilise its’ reasoning skills – it kept thinking times low (often under 20 seconds), meaning it provided a snappy response, being both token and time-efficient – responses to questions barely took 1,000 tokens at most.
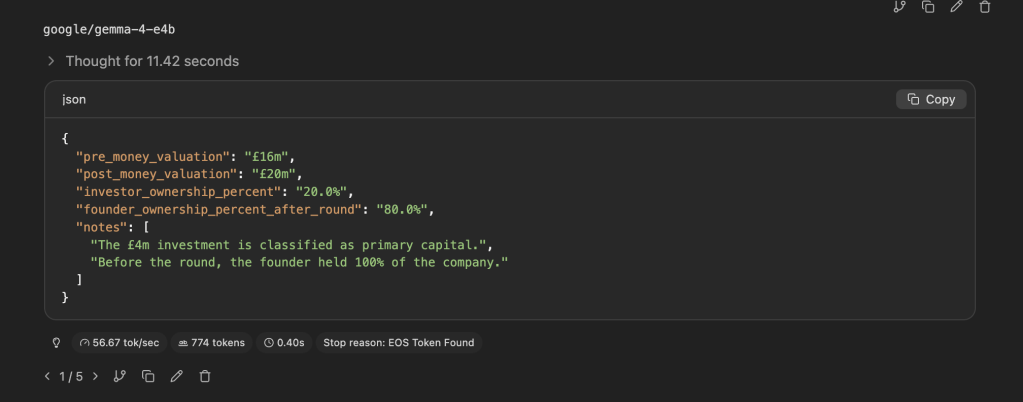
Strengths
- Rapid inference
- Relatively token-efficient
- Reasonable memory constraints
- Excellent explanations
Weaknesses
- Sometimes gets the easy stuff wrong, even if it understands the reasoning
- Still needs a very thorough reader
Best use case
To me, Gemma 4 E4B represents the frontier of a critical niche in local inference AI – a model small enough to run on most desktop devices and laptops (with a small enough context window), whilst demonstrating a reasonable baseline of reasoning. It excels in data analysis and retrieval in paragraph-sized documents.
Provisional verdict
Don’t go giving it root access, but this LLM can really speed up routine data retrieval tasks – with heavy human supervision.
Model 2: Qwen 3.5 9B
The next model I tested was Qwen 3.5 9B – a 9 Billion parameter model. Although slightly older than the Gemma 4 or Qwen 3.6 families, Qwen 3.5 provides a useful bridge to analyse how model capabilities evolve between the 4 Billion edge model class and the multi-dozen parameter ‘flagship’ models of the latest open weight families.
| Detail | Result |
|---|---|
| Model | Qwen 3.5 9B |
| Context length | 262,000 |
| Temperature | 0 |
| Speed | ~35 tokens/sec |
| Memory pressure | 16.8 GB at maximum context (6.1 GB minimum) |
| Scorecard | Score |
|---|---|
| Question 1 | 9 |
| Question 2 | 9 |
| Question 3 | 7 |
| Question 4 | 8 |
| Question 5 | 9 |
| Question 6 | 9.5 |
| Question 7 | 10 |
| Question 8 | 8.5 |
| Question 9 | 9 |
| Question 10 | 7 |
| Total: | 86/100 |
General impression
I had some mixed feelings here. Whilst it’s true that the paper score of 86 out of 100 is marginally higher than the score obtained through Gemma-4-E4B model, this came at a cost. Massively increased inference times. As expected, the 9 billion parameter model conducted inference at a slower rate than the nimble 4 Billion parameter option, or roughly 30% slower. However, what I didn’t expect was the huge increase in reasoning intensity. Whereas the nimbler E4B model was able to conduct all of its’ reasoning using no more than 1,200 tokens in each

And if we look at the reasoning that Qwen 3.5 conducts, it can get a bit… repetitive. When responding to question 3, Gemma 4 E4B required a total of 1,145 tokens and 16.5 seconds of thought. Qwen 3.5 9B took 7,568 tokens and 3 minutes and 45 seconds of thought. The models scored the same.
Strengths
- Larger context window allows longer conversations than Gemma 4-E4B
- Has marginally more reasoning power
Weaknesses
- 30% slower inference than the tested 4B parameter models
- Between 40% and octuple the number of tokens needed for reasoning than Gemma 4 E4B
Best use case
In all honesty, I’m not sure what to make of this model. It exists in a sort of ‘uncanny valley’, where it suffers from worse performance than 4 Billion parameter models, is too large to comfortably run on consumer grade devices with 16 GB of memory at any context length, and guzzles tokens in a way that Gemma models don’t. Although technically capable, you’re much better off sticking to either one of the smaller Gemma models for light work or, if your system permits, a larger model in the 20-30 billion parameter range for true heavy reasoning.
Provisional verdict
Best avoided
Model 3: Gemma 4 26B

Gemma 4 26B is particularly interesting because it’s the first of the two models I tested that exhibit ‘model of experts’ architecture. What this means in practice is that, although it has access to the full knowledge base of its’ 26 billion parameters, it actively utilises only 4 billion parameters of ‘specialised’ knowledge most relevant to each query submitted, allowing it to have the breadth of knowledge of a 26 billion model whilst enjoying the inference speeds of its’ much smaller counterpart
| Detail | Result |
|---|---|
| Model | Gemma 4 26B A4B |
| Context length | 262,144 |
| Temperature | 0 |
| Speed | ~57 tokens/sec in optimal conditions |
| Memory pressure | 35 GB with full context window (16.4 GB minimum) |
| Scorecard | Score |
|---|---|
| Question 1 | 10 |
| Question 2 | 9 |
| Question 3 | 10 |
| Question 4 | 8.5 |
| Question 5 | 7 |
| Question 6 | 10 |
| Question 7 | 10 |
| Question 8 | 9 |
| Question 9 | 8 |
| Question 10 | 10 |
| Total: | 91.5/100 |
General impression
Now we’re getting somewhere. If you had to choose between Qwen 3.5 9B and Gemma 4 26B, the Gemma model is a no brainer if you have the memory to spare. It scores a full ten points higher than the smaller E4B model. Although this is at the cost of slightly more inference per token, it’s nowhere near as much inference as is conducted by Qwen 3.5 9B – and the return to the rapid inference enjoyed by models with 4 billion active parameters makes the experience feel even more fluid
Strengths
- Rapid inference
- Efficient reasoning
- High accuracy
Weaknesses
- Marginally less token efficient than Gemma 4 E4B
- The first of the ‘RAM guzzlers’ – takes triple the memory of the 4 billion parameter model.
Best use case
Gemma 4 26B is very much a ‘best of both’ workhorse for my use case – its’ depth of knowledge combined with speed of inference makes it utterly perfect for my daily workflows on this machine.
Provisional verdict
A strong model, suitable for most day to day work on higher end consumer devices
Model 4: Gemma 4 31B

Gemma 4 31B is the ‘densest’ model I tested. In other words, it’s the model with the largest number of parameters active at any one time. Whilst this should in theory make it even more capable than its ‘sparse’ model of experts sibling, it comes at the cost of context being much more memory intensive (to the point that my machine was unable to load the model with its’ full context window)
| Detail | Result |
|---|---|
| Model | Gemma 4 31B |
| Context length | 262,144 |
| Temperature | 0 |
| Speed | 11 tokens/sec |
| Memory pressure | 19.5-87 GB (dependent on Context window) |
General impression
| Scorecard | Score |
|---|---|
| Question 1 | 10 |
| Question 2 | 9 |
| Question 3 | 10 |
| Question 4 | 10 |
| Question 5 | 8.5 |
| Question 6 | 10 |
| Question 7 | 10 |
| Question 8 | 10 |
| Question 9 | 9.5 |
| Question 10 | 10 |
| Total: | 97/100 |
As you can see, on paper this is our most capable model yet, cruising through the question set. It also happens to be the most token-efficient, with its’ reasoning taking significantly fewer tokens than model counterparts, with this question taking Gemma 4 31B just 567 tokens to answer compared to 944 from Gemma 4 26B.
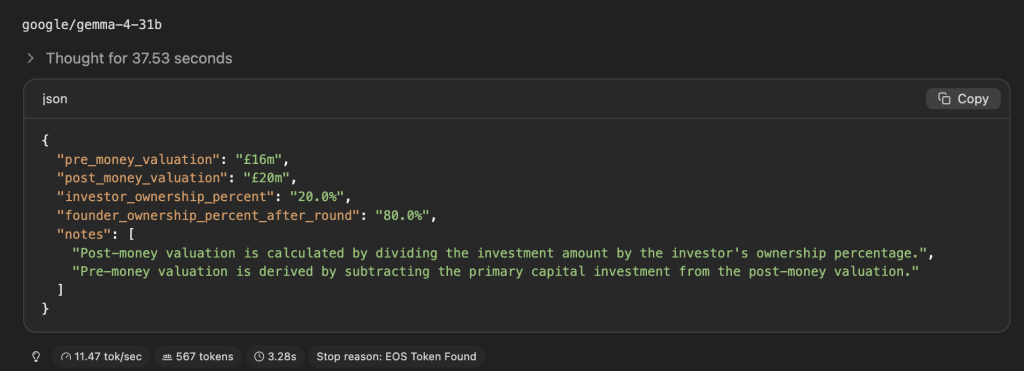
However, the cripplingly low inference speed on my device mean it’s very hard to take this model seriously as a day-to-day workhorse
Strengths
- Extremely thorough reasoning
- Token-efficient response
Weaknesses
- Much slower than anything else tested
Best use case
For my hardware, the best use case of Gemma 31B is clear – it’s far too slow (not to mention memory intensive) for most questions. Nevertheless, when a particularly complex or large data retrieval task or analysis that other models may struggle with comes up, switching from other models to Gemma 31B for that issue, then switching back allows me to gain pinpoint-accuracy at a fraction of the context cost of other models. Additionally, only using it for these rare questions allows my workflow to keep going on at a reasonable rate.
Provisional verdict
A heavy hitter, best used when real firepower is needed.
Model 5: Qwen 3.6 35B A3B
This model is, paradoxically, both the largest and the smallest of the models. It has the largest number of total parameters, but the smallest number of active parameters. It’s also the only model being tested out of the Qwen 3.6 family, the latest open weight model being released by Alibaba Cloud. The question that’s a deal-maker or breaker for me was: is this model’s token-efficiency superior to that of the smaller and older Qwen 3.5 9B, perhaps on par with Gemma models?
| Detail | Result |
|---|---|
| Model | Qwen 3.6 35B A3B |
| Context length | 262,144 |
| Temperature | 0 |
| Speed | ~51 tokens per second |
| Memory pressure | 21.6-26.6 GB |
| Scorecard | Score |
|---|---|
| Question 1 | 10 |
| Question 2 | 10 |
| Question 3 | 10 |
| Question 4 | 9 |
| Question 5 | 10 |
| Question 6 | 10 |
| Question 7 | 7 |
| Question 8 | 10 |
| Question 9 | 10 |
| Question 10 | 10 |
| Total: | 96/100 |
General impression
A decent score. However, the ‘model of experts’ architecture at larger sizes does appear to come with some tradeoffs – despite having more total parameters than Gemma 4 31B and being of the ‘same generation’, Qwen 3.6 35B scored lower (albeit marginally) – when all vectors aren’t brought to bear on a problem, there is always a small chance that some potentially relevant parameters were excluded from the active subset, impacting performance.
But the main question that’s relevant to me – what were inference times like?

The side by side inference times between Qwen 3.6 35B and Gemma 4 31B were impressive indeed. Although it’s undeniable that Qwen 3.6’s reasoning tended to use more context, it was more token-efficient than its’ sibling from the last generation that we tested earlier. This, combined with the 50 tokens per second inference speeds meant that the sparse Qwen model delivered substantially shorter thinking periods than Gemma 4 31B in 9 out of the 10 questions in the set.
Strengths
- Fastest in terms of ‘tokens per parameter’
- Gemma 4 31B level performance
Weaknesses
- Highest base memory requirements
- Thinking is a little verbose and hard to parse
Best use case
High-speed, large-scale automated processing where rapid response time is prioritized over deep reasoning.
Provisional verdict
A highly efficient specialist for large-throughput tasks.
Large models versus small models
The most useful comparison was not only model against model, but class against class.
The large models – Qwen 3.6 35B, Gemma 4 31B and Gemma 4 26B – were tested as serious local assistants. Their advantage should be depth: better reasoning, better writing, stronger coding support and more reliable handling of complex prompts.
The small models – Qwen 3.5 4B and Nemotron 3 Nano 4B – were tested as lightweight tools. Their advantage should be speed: fast responses, lower memory use and less friction.
The key finding to explore is whether the large models were merely better, or whether the smaller models had a genuine role. In local AI, speed is not a minor factor. A model that answers in two seconds may be more useful for routine tasks than a smarter model that takes thirty seconds to produce an answer.
This is especially relevant for business use. Many business tasks do not require deep reasoning. Classification, tagging, rough summaries, first drafts and simple extraction may not need a dense, multi-dozen billion parameter model. But complex analysis, coding and source-grounded reasoning probably do.
Results summary
Scorecard Summary
Model Comparison Profile
| Model | Raw capability | Practical speed | Best use case | Main weakness |
|---|---|---|---|---|
| Qwen 3.6 35B | High | Fast (~51 tps) | Automated throughput | Verbose/Memory intensive |
| Gemma 4 31B | Highest | Slow (11 tps) | Complex analysis | Extreme latency |
| Gemma 4 26B | High | Very Fast (~57 tps) | Daily workhorse | RAM requirements |
| Qwen 3.5 9B | Moderate | Moderate (~35 tps) | Lightweight tasks | Inefficient reasoning tokens |
| Gemma 4 4B | Low | Fast (~52 tps) | Simple extraction/retrieval | Lower intelligence |
Best model by task
| Use case | Best model | Reason |
|---|---|---|
| Best overall local assistant | Gemma 4 26B A4B | Perfect balance of speed and accuracy |
| Best reasoning model | Gemma 4 31B | Highest raw score in the test set |
| Best coding model | Gemma 4 31B | Superior intelligence for complex logic |
| Best writing model | Gemma 4 31B | Highest linguistic capability |
| Best structured-output model | Gemma 4 31B | Most reliable adherence to JSON schema |
| Fastest usable model | Gemma 4 E4B | High speed with acceptable accuracy |
| Best small model | Gemma 4 E4B | Remarkably high score for 4B size |
| Best balance of speed and quality | Gemma 4 26B A4B | High performance without the massive latency |
| Most capable but least practical | Gemma 4 31B | Too slow for real-time interaction |
| Biggest surprise | Gemma 4 E4B | Achieved >80% score despite tiny size |
| Biggest disappointment | Qwen 3.5 9B | The “uncanny valley” of inefficient token usage |
Business implications
The results have broader implications beyond laptop experimentation.
The first is that local AI is becoming practical. Running models in the 26B–35B range on a consumer laptop would once have seemed unrealistic. Now, with sufficient unified memory and good local tooling, it is possible to run models that are genuinely useful.
The second implication is that businesses should not think about local LLMs as a single category. A small local model and a large local model serve different purposes. A 4B model may be suitable for fast internal classification, simple summarisation or low-stakes automation. A 30B-class model may be more appropriate for reasoning-heavy analysis, coding or document review.
The third implication is that model deployment will become more hybrid. Cloud models will remain important for frontier-level reasoning, reliability and polished user-facing applications. But local models will increasingly make sense where privacy, cost control or offline access matter.
A company might use a small local model to triage documents, a larger local model to draft internal summaries, and a frontier cloud model only for the most difficult or high-stakes tasks. This kind of routing could become one of the most important practical patterns in AI adoption.
The fourth implication is that evaluation matters. The model that feels most impressive in conversation may not be the best operational model. For businesses, the important questions are:
- Can it follow instructions?
- Can it produce valid structured output?
- Can it avoid hallucinating?
- Can it run at acceptable speed?
- Can it handle the actual documents or workflows involved?
- Can its mistakes be detected?
The answers vary by model.
Final comparison
My provisional final ranking is:
- Gemma 4 26B A4B
- Qwen 3.6 35B A3B
- Gemma 4 31B
- Gemma 4 E4B
- Qwen 3.5 9B
The best overall model was Gemma 4 26B A4B, because it offers the highest intelligence-to-speed ratio for daily workflows.
The best large model was Gemma 4 31B, because it achieved the absolute highest accuracy score in the test set.
The best small model was Gemma 4 E4B, because its performance at only 4 billion parameters is remarkably robust.
The most practical model was Gemma 4 26B A4B, because it provides near-top-tier intelligence without the crippling latency of denser models.
The most capable but least convenient model was Gemma 4 31B, because its inference speed makes real-time interaction frustrating.
The biggest surprise was Gemma 4 E4B‘s high score relative to its small size.
The biggest disappointment was Qwen 3.5 9B due to its inefficient and repetitive reasoning process.
Conclusion
Testing these 5 promising models showed me just how quickly local AI is becoming practical.
The larger models demonstrate that laptop-based inference is no longer limited to toy examples. They can be genuinely useful for writing, reasoning, coding and analysis. But they also show the cost of local capability: slower responses, greater memory pressure and more friction.
The smaller models show the opposite trade-off. They are less capable, but often much faster and more convenient. For many routine tasks, that’s more than enough.
That is the real lesson from local LLM testing. The question is not simply which model is “best”. The question is which model is best for a given job.
For individuals, local models offer privacy, experimentation and control. For businesses, they suggest a future in which AI workloads are distributed across different model sizes and deployment environments, with routine and commercially sensitive tasks running locally on workstations, whilst larger tasks will remain relegated to the cloud or proprietary servers.
The local LLM market is therefore not just a technical curiosity. It is part of a broader shift in AI economics. As models become easier to run, the advantage will move from merely having access to AI towards knowing how to choose, test and deploy the right model.
The next stage of AI adoption will not be defined only by the largest models. It will also be defined by the models that are fast enough, private enough and reliable enough to be useful where the work actually happens.

Leave a comment